Daily Covid-19 Stats Nº 16
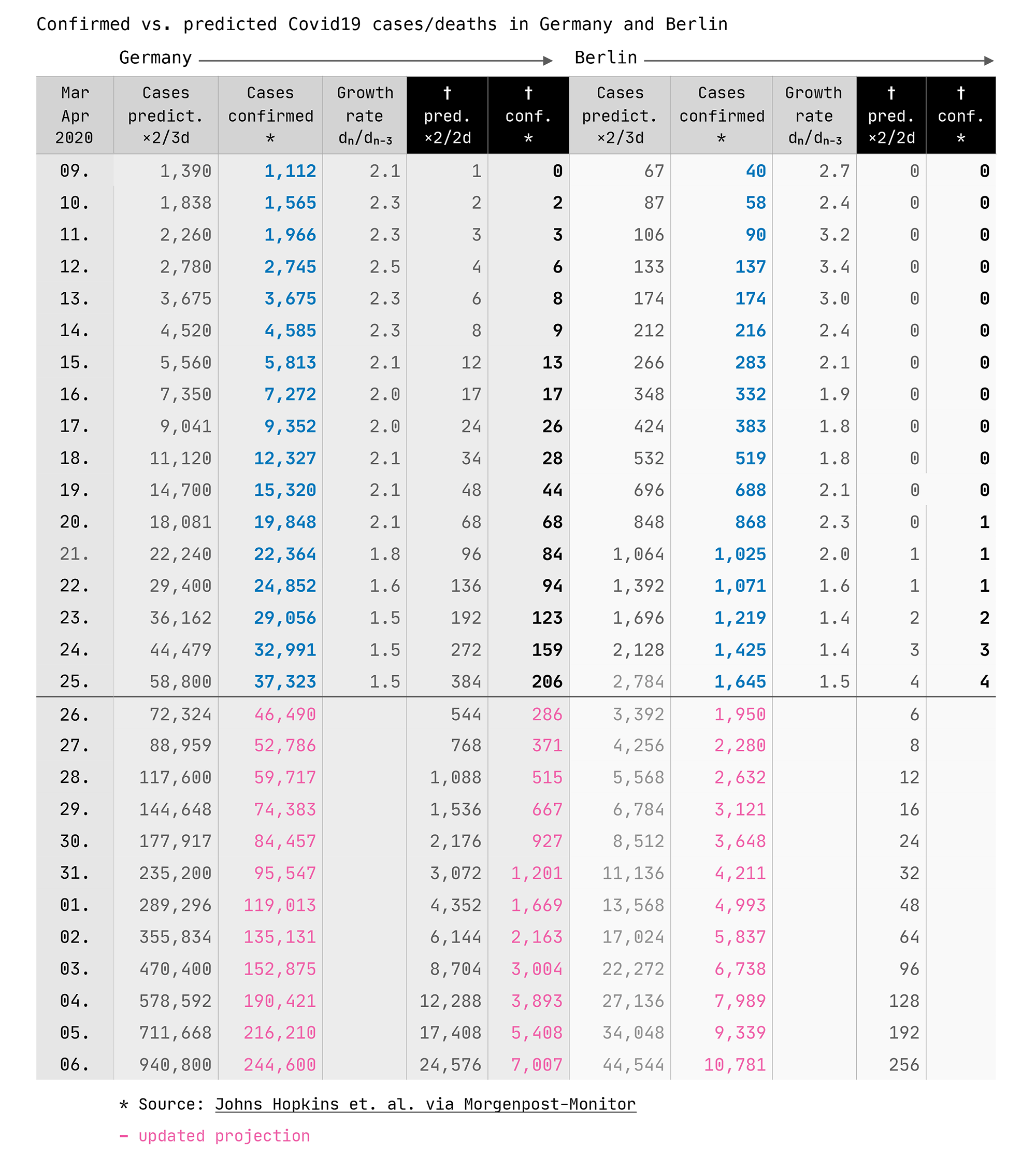
Coronavirus spreadsheet: registered Cases and Deaths in Germany and Berlin today
End of Day Summary (16). The number of registered cases in Germany has increased today by 4,332, with a growth rate identical to that of the last 2 days (×1.5 per 3 days). The number of deaths is increasing faster than the number of cases, with a growth rate of ×1.7 per 2 days. In Berlin we recorded the 4 deaths, which means that the reality corresponds exactly with the projection.
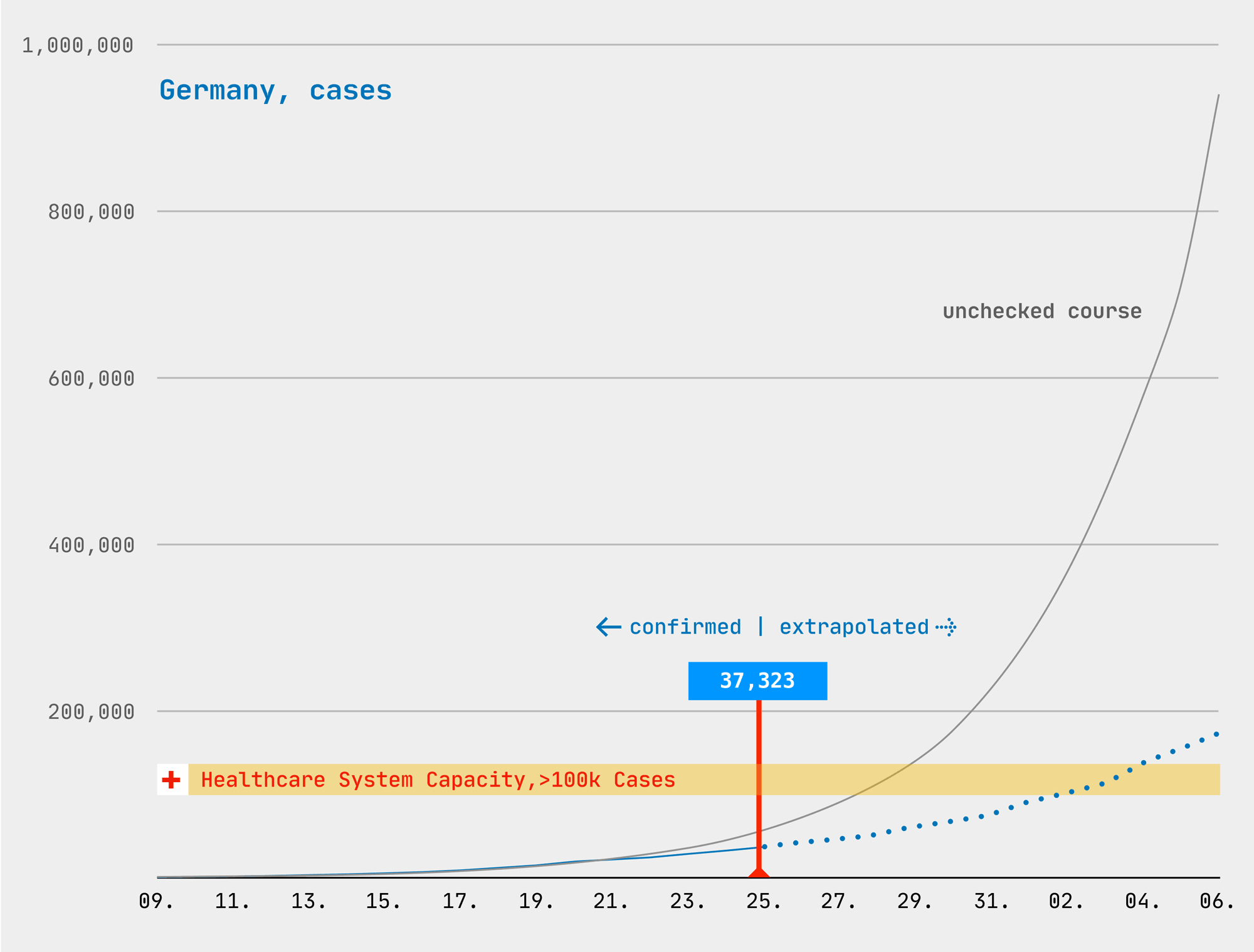
Coronavirus Curves for Germany, predicted cases vs. confirmed cases, March 25, 2020
The curve of confirmed cases (blue) is flatter than the statistical prediction (gray) and the growth rate did not change compared to yesterday. Today’s news announced that about 1000 patients are in intensive care in Germany. There are currently 4,500 ICUs available, which means that our health system reaches its limits above 100,000 registered cases … but this barrier must still be treated with caution.
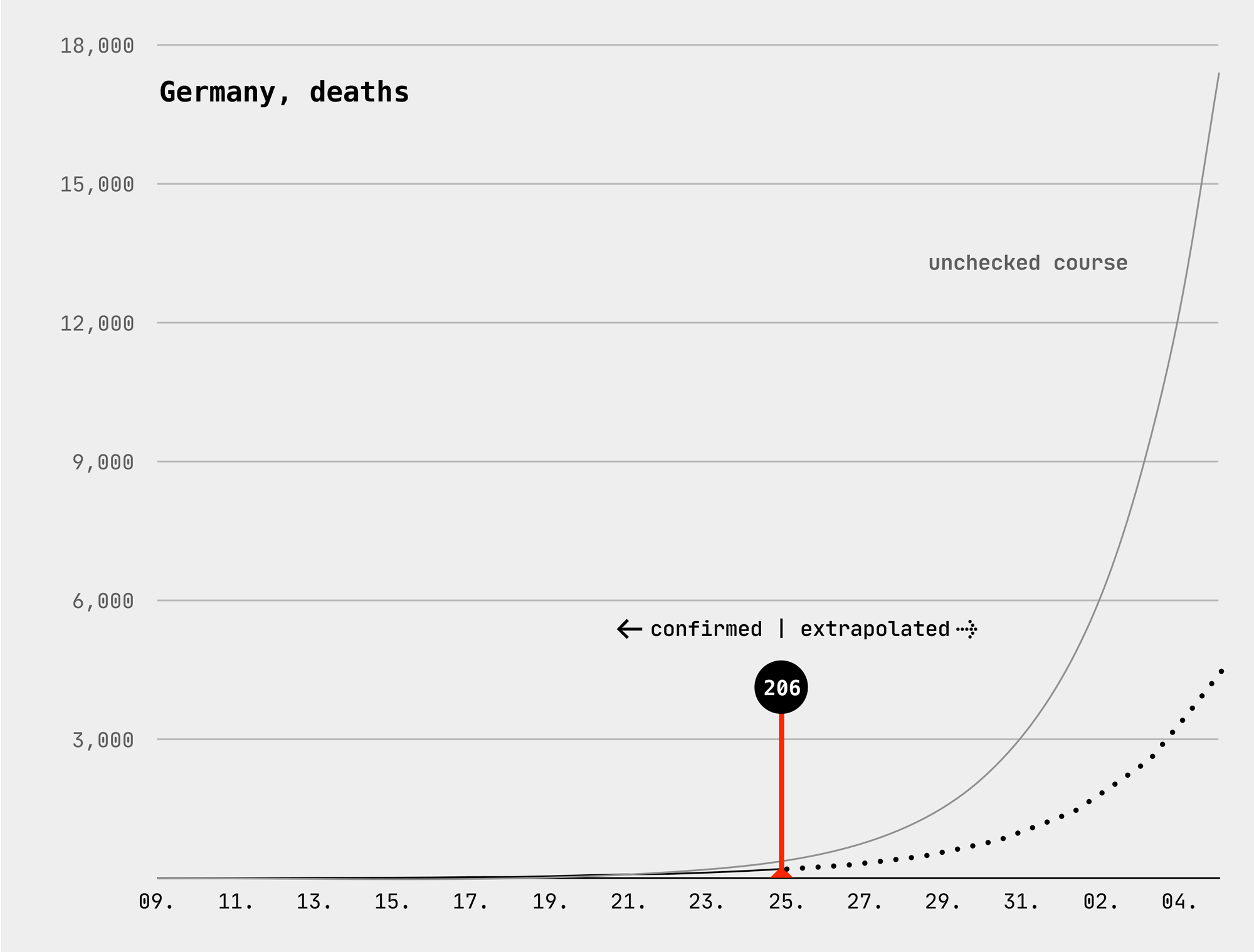
Coronavirus Curves for Germany, predicted deaths vs. confirmed deaths, March 25, 2020
The number of deaths is becoming more dynamic. It may not double in two days, but it grows ×1.7, just like yesterday.
Author’s note: The above values are purely speculative estimations using simple mathematical modelling (based on registered cases/deaths) and are not confirmed by health authorities nor any other national public authority.
Warum eine eigene Coronavirus-Statistik?
Drei schnelle Antworten vorweg:
- Weil ich die Vergangenheit festhalten möchte
- Weil ich die Gegenwart verstehen möchte
- Weil ich in die Zukunft blicken möchte
Und dies alles zusammen liefern mir weder die Statistiken der Meldestellen, noch der Medien.
Wie so oft begann bei mir alles mit einer Unzufriedenheit über die Gestaltung der „amtlichen“ Charts: Schrift, Farbe, Übersichtlichkeit. Bald merkte ich, dass die von den Medien gelieferten Statistiken auch meine Fragen nicht beantworteten. Schließlich erwachte der Forschergeist in mir, weil ich mich an die tagelangen Messungen und Kurven während meines Physikstudium erinnerte, aus denen ich belastbare Ergebnisse herauszulesen versuchte.
Die erste Visualisierung der Covid19-Entwicklung, die Anfang März die große Runde im Netz machte, war die schwarze Landkarte mit den roten Luftballons, ins Netz gestellt von der Johns Hopkins University (Baltimore, Maryland, USA): COVID-19 tracking map. Diese und andere Statistiken (zum Beispiel des Robert Koch Instituts) nehmen drei Parameter unter die Lupe: (1) die Anzahl der registrierten Fälle, die (2) Summe der Verstorbenen und die (3) Zahl der Genesenen, wobei die beiden letzteren übrigens Untermengen von (1) sind, also darin enthalten. Was mir bei diesen Karten fehlte, war der zeitliche Verlauf.
Leider ist gerade die erste Variable (Fallzahl) die unsicherste. Sie basiert auf den Ergebnissen von Tests, die in den einzelnen Ländern sehr unterschiedlich gehandhabt werden. Weil es die Kapazität des Gesundheitswesens nicht leisten kann, alle Menschen (mit oder ohne Symptome) zu testen, muss eine Auswahl getroffen werden. Flussdiagramme helfen bei der Entscheidung, ob man überhaupt eine Chance auf einen Test hat (hier ein Beispiel auf Zeit Online: Habe ich mich mit dem Coronavirus angesteckt?).

Die Covid-19 Tracking-Karte der Johns-Hopkins-Universität dient vielen Experten als Datenquelle für die Beobachtung der Coronavirus-Pandemie-Entwicklung
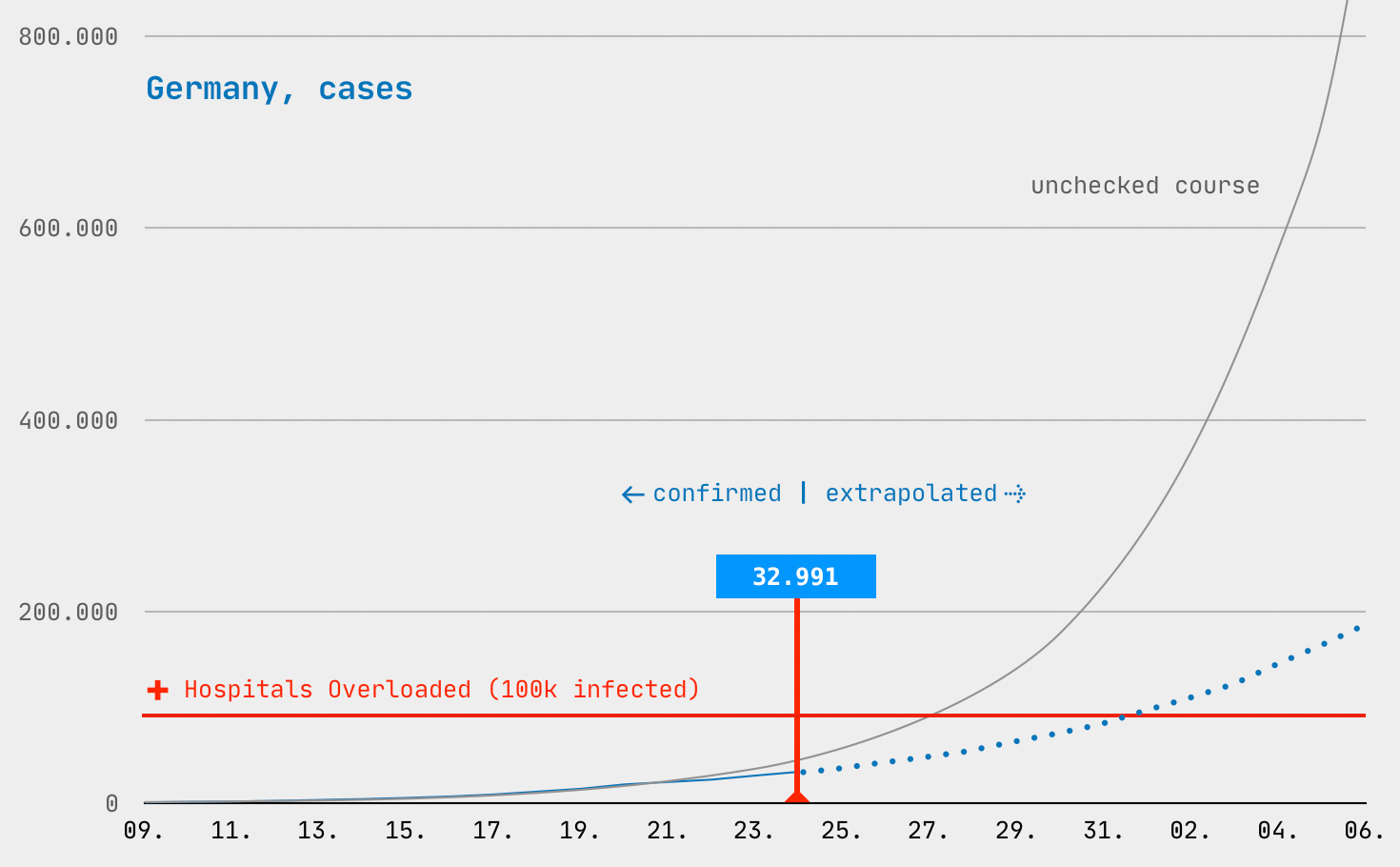
Es ist also davon auszugehen, dass weit mehr Menschen mit dem Coronavirus infiziert sind, als die statistische Zahl der registrierten Fälle wiedergibt. Wie hoch diese Dunkelziffer ist, weiß derzeit niemand. Was allerdings ziemlich zuverlässig gezählt wird, ist die Zahl der Verstorbenen. Die aktuell vergleichsweise geringe Zahl der Toten in Deutschland (heute 159, bei 33.000 registrierten Fällen) weist laut Experten darauf hin, dass in Deutschland mehr getestet wird als zum Beispiel in Spanien (2991 Tote, 42.000 Fälle) oder in den USA (801 Tote, 55.000 Fälle); so lässt sich erahnen, in welchen Dimensionen sich die registrierten Fälle dieser beiden Länder tatsächlich bewegen müssten … sie stehen noch vor großen Herausforderungen.
Wichtig ist auch zu erwähnen, dass die Zahl der registrierten Fälle bezüglich des Fortschritts der Pandemie immer ein Blick zurück ist. Das ergibt sich aus der Inkubationszeit des Virus (5 – 6 Tage), plus der Zeit für den Test, das Warten auf das Ergebnis, das Melden an die Gesundheitsämter und deren Veröffentlichung … alles in allem 10, wenn nicht gar 12 Tage.
Warum nehme ich die Daten von Johns Hopkins und nicht die vom Robert Koch-Institut?
Mir fiel von Anfang an auf, dass die Zahlen von Johns Hopkins nicht nur die höheren waren, sondern auch übers Wochenende konstant weiterliefen, wenn Gesundheitsämter nur spärlich besetzt sind. Der Grund: Johns-Hopkins-Mitarbeiter suchen und zapfen aktiv öffentlich zugängliche Quellen ab, zum Beispiel die Internetseiten von Gesundheitsbehörden, die Website der WHO, und laut welt.de „auch eine Community von Medizinern, die Medienberichte und Twitteraccounts von Behörden analysieren. Damit geben die Zahlen der Johns-Hopkins-Universität nahezu in Echtzeit das Lagebild wieder.“ So ähnlich würden das auch andere Datensammler machen, zum Beispiel Risklayer. Die WHO-Daten stammten von den nationalen Behörden und geben den Datenstand von 10 Uhr mitteleuropäischer Zeit wieder.
Um abschätzen zu können, welche Maßnahmen gegen die Corona-Pandemie sinnvoll sind, benötigen Politik und Wissenschaft verlässliche Daten. Doch wie auch der SPIEGEL gestern feststellte: Die Fallzahlen des Robert Koch-Instituts (RKI) hinken der Realität teils mehrere Tage hinterher (Die große Meldelücke). Unser föderales System bringt es mit sich, dass in den Bundesländern unterschiedliche Behörden die Daten erfassen, bündeln und zu verschiedenen Zeiten veröffentlichen. Generiert werden die Daten in Testlaboren, die Coronafälle innerhalb von 24 Stunden an die örtlichen Gesundheitsbehörden melden, also Stadt oder Landkreise. „Das geschehe in der Regel per Fax“ zitiert der SPIEGEL einen Behördenmitarbeiter. Daraufhin werden sie händisch in ein digitales Meldesystem eingegeben, das sie an die Landesbehörden übermittelt. Diese importieren die Fallzahlen in eine Datenbank und senden sie um 15 Uhr an das RKI.
Ich nutze die Zahlen von Johns Hopkins, die ich einer ziemlich gut gestalteten und gepflegten interaktiven Website der Berliner Morgenpost entnehme: Coronavirus Echtzeitkarte. Dort ist auch ein hilfreicher Rückwärts-Schieberegler integriert.
Die Spielregeln der Virus-Pandemie
Ich habe mit meiner Statistik vor rund drei Wochen begonnen, als die ersten Maßnahmen beschlossen wurden: ein Fußball-Bundesligaspiel ohne Zuschauer, die Eishockey-Liga brach gerade ihre Saison komplett ab, Berlin schloß alle Opern und Theater, Businesskonferenzen werden reihenweise abgesagt und am Abend gab James Blunt sein Konzert in Hamburg vor leeren Rängen. Alles begann mit einer simplen Tabelle, in der ich die aktuellen und zurückliegende Fallzahlen und Todesfälle eintrug, für Deutschland und Berlin. Dem hoch geschätzten Podcast von NDR Info Das Coronavirus-Update mit Christian Drosten habe ich an diesem Tag entnommen, dass sich die Epidemie – basierend aus den Erfahrungen in China und Italien – nach folgenden 3 Spielregeln ausbreitet:
- Die Zahl der gemeldete Fälle verdoppelt sich alle 3 Tage
- Die Zahl der gemeldeten Fälle ist in 3 Wochen die Zahl der Toten und/oder
- Die Zahl der Toten verdoppelt sich alle 2 Tage
Das ist die Ausbreitungsmathematik für eine ungebremste Entwicklung des Coronavirus. Und sie verläuft exponentiell, denn nichts anderes bedeutet multiple Verdopplung: 2 hoch n, oder auch 2ⁿ geschrieben. Es fällt uns Menschen schwer, die Dramatik eines exponentiellen Wachstums zu verstehen. Unser Gehirn kann nur linear. Mancher erinnert sich vielleicht an die Anekdote vom indischen Kaiser Sheram, der den Erfinder des Schachspieles belohnen wollte, weil er großen Gefallen an dem Spiel fand. Der Erfinder sollte einen Wunsch äußern, worauf dieser sagte: „Händige mir für das erste Feld des Schachbrettes 1 Reiskorn aus, 2 Körner für das zweite Feld, 4 für das dritte und für jedes weitere Feld doppelt so viele Körner wie für das vorhergehende“. Der Kaiser fühlte sich gekränkt, da ihm das Ausmaß des Wunsches noch nicht bewusst war. Als digitalisierte Menschen, Freunde des Dualsystems und Käufern von Computern ist uns die Zahlenreihe 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 und 1024 durchaus bekannt und wir wissen daher, dass auf dem 10. Feld des Schachbretts bereits 512 Reiskörner liegen, summiert mit den Feldern davor sind das 1023 Reiskörner. Kurz und gut: die Reiskornzahl des 64. Feldes liegt über 9 Trillionen (eine 19-stellige Zahl), die Anzahl der Reiskörner auf allen Feldern ist 20-stellig. Bei 3 g Gewicht pro Reiskorn ergeben sich 540 Milliarden Tonnen Reis, was 873 Jahresernten Reis entspricht. Danke an Jennifer, Theresa, Sabrina, Charlina & Birte von der TU München fürs Ausrechnen (PDF).
Zurück zur Entwicklung der Coronavirus-Fallzahlen in Deutschland. An dem Tag, als ich meine Tabelle begonnen habe (12. März), lag die Zahl der gemeldeten Fälle bei 2.745, drei Tage später bei 5.813, wieder drei Tage später bei 12.327 … ich habe später noch die Woche zuvor erfasst und festgestellt, dass sich die Zahl der Fälle über zwei bis drei Wochen wie ein Uhrwerk gemäß den Vorhersagen entwickelt hatte.
Das war die Zeit, als Bundesgesundheitsminister Jens Spahn täglich vors Mikrofon trat und sofortige Maßnahmen forderte. Was er nicht sagte, aber wusste: Entwickeln sich die Fälle und die Todeszahlen ungebremst weiter wie bisher, hätten wir in Deutschland am Ende der ersten April-Woche bereits 1 Million gemeldeter Fälle und rund 20.000 Tote. Das sagte mir jedenfalls meine Tabelle, die ich zu dieser Zeit noch nicht mit den April-Zahlen auf Twitter veröffentlichte, sondern nur bis zum 31. März.
Was ich aber tatsächlich mit meiner eigenen Tabelle herausfinden wollte, und das ist keiner mir bekannten Statistik zu entnehmen: Wann und wie stark greifen die Maßnahmen, die zunehmend schärfer wurden, bis zur Kontaktsperre vor 3 Tagen? Dazu braucht es nur zwei Kurven (siehe oben), nämlich die ungebremste und die gemeldete Entwicklung (vom Fällen und Toden), wobei ich die gemeldeten Zahlen ab jedem Stichtag hochrechnete, mit der gerade geltenden Wachstumsrate. Seit Sonntag liegt die Wachstumsrate unter 2.0 (also keine Verdopplung mehr), aktuell liegt sie bei den Fällen bei 1.5 und bei den Toden bei 1.4.
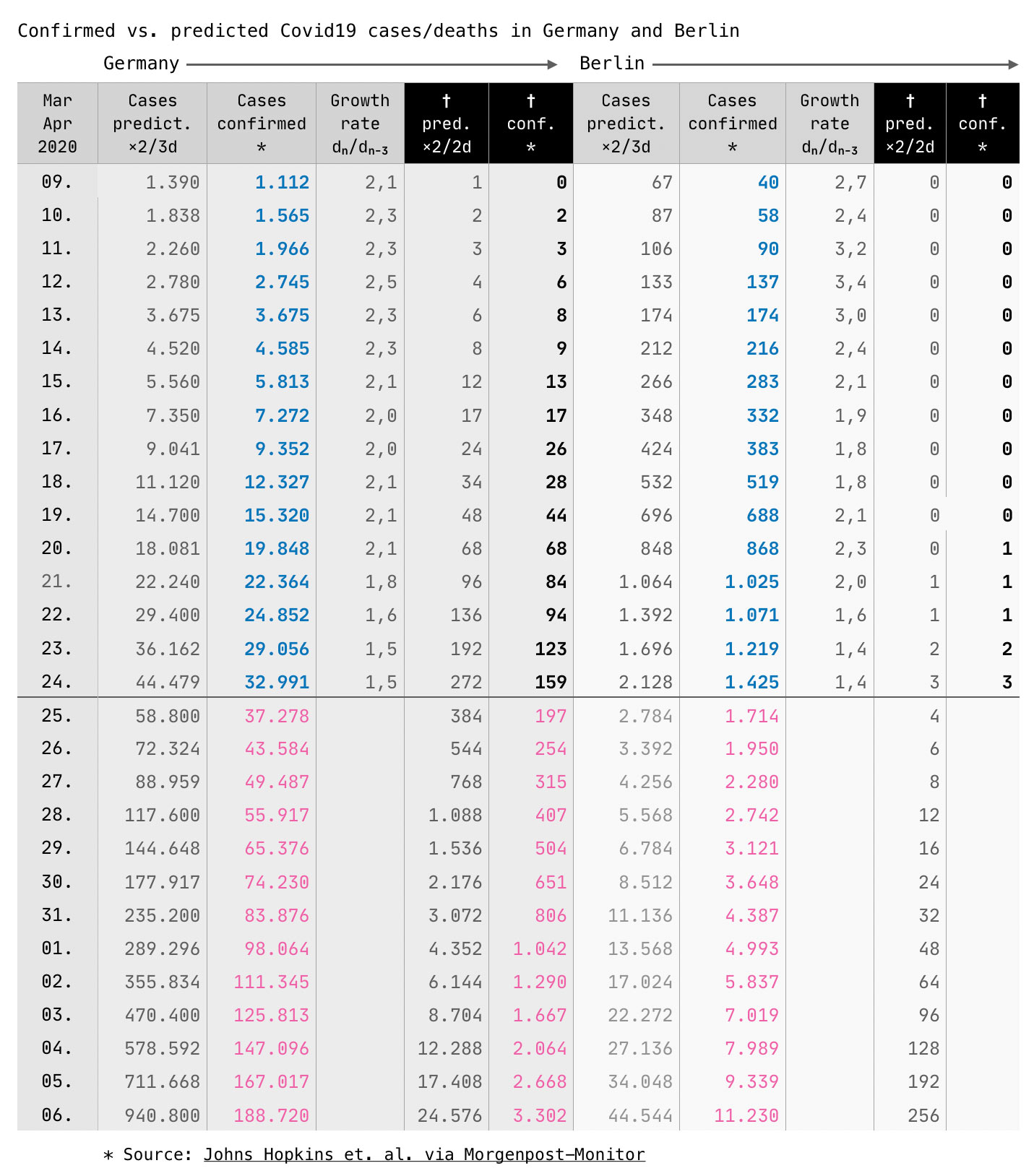
Meine tägliche Coronavirus-Tabelle für Deutschland und Berlin stellt die bestätigten Fälle (blau) und Tode (schwarz) den internationalen Erfahrungswerten für ungebremste Ausbreitung gegenüber (grau); in magenta die Hochrechnungen, basierend auf den am Stichtag geltenden (gebremsten) Wachstumsraten.
[wird fortgesetzt]
Deep Speed Typography

Drei Semester Zeit für ein eigenes Typografie-Projekt. Workshops, Exkursionen, Teamarbeit: Der neue Master der Hochschule Mainz startet im Oktober 2020. Virtueller Info-Termin am 1. April 2020.
Es gibt typografische Gestaltung für das tiefe Verständnis (Deep Reading) und Typografie für den schnellen Überblick (Speed Reading). Beide Lesearten und ihre visuelle Aufbereitung sollen in einem neuen Masterstudiengang der Hochschule Mainz intensiv beleuchtet werden. Dabei wird mittels gestalterischer Experimente zunächst ermittelt, worauf sich ein eigenes Master-Projekt fokussieren könnte: Ein besseres Instagram, eine eigene Schrift, die Lese-App der Zukunft, ein generatives Buch, Typografie für Augmented Reality, Moving-Posters, das Editorial Design von morgen oder das, woran noch niemand gedacht hat.
Der Master richtet sich sowohl an Typografie-/Editorial Design-Nerds als auch an diejenigen, die noch etwas nachholen wollen: typografische Expertise, technische Hintergründe, Nachdenken über Gestaltung — oder einfach mehr Projekterfahrung. Solche Studiengänge dienen darüber hinaus als solide Kontaktbörse für den Einstieg ins Berufsleben.
Mit Workshops von Jakob Runge (Schriftentwerfer), Frank Rausch (Interface-Typograf) und Underware (Foundry).
Neuerscheinung: »100 Jahre Kommunikationsdesign«
 Kommunikationsdesign ist überall, und trotzdem schwer zu definieren. Angesiedelt zwischen angewandter Kunst und Dienstleistung, Handwerk und Beratung, Avantgarde und Mainstream hat sich diese Sparte des Designs erst in den letzten 20 Jahren zu einem stabilen Industriezweig entwickelt, der endlich auch in den Statistiken von Wirtschaftsverbänden und -ministerien Einzug gehalten hat.
Kommunikationsdesign ist überall, und trotzdem schwer zu definieren. Angesiedelt zwischen angewandter Kunst und Dienstleistung, Handwerk und Beratung, Avantgarde und Mainstream hat sich diese Sparte des Designs erst in den letzten 20 Jahren zu einem stabilen Industriezweig entwickelt, der endlich auch in den Statistiken von Wirtschaftsverbänden und -ministerien Einzug gehalten hat.
Die neue BDG-Publikation »Avantgarde und Mainstream: 100 Jahre Kommunikationsdesign in Deutschland« beleuchtet die große Erfolgsgeschichte der Disziplin von den Anfängen der Gebrauchsgrafik zu Beginn des letzten Jahrhunderts bis zum UX-Design von heute. Zum 100. Geburtstag des BDG, der die Designerinnen und Designer auf diesem Weg begleitet, widmen sich 16 Fachautorinnen und -autoren dem gesellschaftlichen Kontext und den Wechselwirkung zwischen Entwerfen und Nutzbarmachen von Kommunikationsdesign. Darüber hinaus bieten sie auch einen Ausblick auf den Designberuf der Zukunft.
Avantgarde und Mainstream: 100 Jahre Kommunikationsdesign in Deutschland, Hrsg. von Rainer Funke, Marion Godau, Christa Stammnitz, Stuttgart 2019, 240 Seiten, ISBN 9783899863185, 34 €. Mit Beiträgen von: Wolfgang Baum, Matthias Beyrow, Petra Eisele, Sabine Foraita, Rainer Funke, Marion Godau, Michael Hardt, Boris Kochan, Anita Kühnel, Jakob Maser, Julia Meer, Jens Müller, Florentine Nadolni, Oliver Ruf, Erik Spiekermann und Christa Stammnitz.
Reformierte »DIN 16507-2 Schriftgrößen« kann kommentiert werden
 Dass sich das Deutsche Institut für Normung mit Schrift und Typografie beschäftig, wissen wir spätestens seit April 2013, als die reformierte DIN 1450 Leserlichkeit erschien, an der erstmals auch Typografen und Schriftentwerfer mitwirkten (die ganze Geschichte: Warum eine Norm zur Leserlichkeit von Schrift sinnvoll ist). Der Nutzen einer Norm für gestalterische Arbeit ist umstritten. Unumstritten ist allerdings auch, dass hierzulande Ingenieure und gewichtige Auftraggeber großen Respekt vor Industrienormen haben. Wenn also weiche Argumente nicht zünden, können Kommunikationsdesigner, Mediengestalter, Werbetechniker und Textverarbeitender zum DIN-Hammer greifen, um ihre Auftraggeber in Sachen Schriftart und Schriftbenutzung zu überzeugen.
Dass sich das Deutsche Institut für Normung mit Schrift und Typografie beschäftig, wissen wir spätestens seit April 2013, als die reformierte DIN 1450 Leserlichkeit erschien, an der erstmals auch Typografen und Schriftentwerfer mitwirkten (die ganze Geschichte: Warum eine Norm zur Leserlichkeit von Schrift sinnvoll ist). Der Nutzen einer Norm für gestalterische Arbeit ist umstritten. Unumstritten ist allerdings auch, dass hierzulande Ingenieure und gewichtige Auftraggeber großen Respekt vor Industrienormen haben. Wenn also weiche Argumente nicht zünden, können Kommunikationsdesigner, Mediengestalter, Werbetechniker und Textverarbeitender zum DIN-Hammer greifen, um ihre Auftraggeber in Sachen Schriftart und Schriftbenutzung zu überzeugen.
Neben der DIN 1450 gibt es weitere Normen, die sich um Schrift drehen, darunter die DIN 16507 aus dem Jahr 1999 zum Thema Schriftgrößen. Es geht um so grundlegende Fragen wie: Welche Größen rund um die Buchstaben gibt es überhaupt? Warum ist der »einfache Zeilenabstand« größer als die Schriftgröße? Wann berühren die Unterlängen die Versalakzente der nächsten Zeile? Welche Schriftgröße muss ich eingeben, um die Leserlichkeit einer Schrift bei einem gegebenen Betrachtungsabstand gewährleisten zu können?
Der Schriftentwerfer Albert-Jan Pool (FF DIN) arbeitet eng mit dem Institut für Normung zusammen und ist inzwischen Obmann des DIN-Ausschuss »Schriften«. Seit Jahren kämpft er für eine Reform der DIN 16507. Nun liegt der Entwurf vor und steht zur Diskussion. Gegenüber Fontblog erläutert Pool die Notwendigkeit dieser Norm: »Unsere Gesellschaft altert und dementsprechend wächst die Zahl der Menschen mit verringerter Sehschärfe. Der Bedarf an leserlich gestalteten Texten nimmt folglich zu und wird in den nächsten Jahrzehnten weiter wachsen.«
Die überarbeitete DIN 16507-2 Schriften – Schriftgrößen dient der Ermittlung, Bestimmung, Festlegung und Angabe von Schriftgrößen und Zeilenabständen. Hierzu beschreibt sie die wichtigsten Maße einer Schrift in Bezug auf die Schriftgröße. Faustregeln erleichtern die Berechnung einer Schriftgröße in pt bei einer zu gewährleistenden Mittellänge oder Ziffernhöhe in mm. Darüber hinaus werden neue Anforderungen an Typometer gestellt: Sie sollen nun auch die Vermessung der Mittellängen und Ziffernhöhen in Printmedien und an Bildschirmen erleichtern und deren Bezug zur Schriftgröße vermitteln. Schließlich wurde die reformierte Norm an die bereits aktualisierten Fassungen der DIN 1450 Schriften – Leserlichkeit und DIN 1451-1 Schriften — Serifenlose Linear-Antiqua — Teil 1: Allgemeines angepasst.
Der Entwurf der aktualisierten DIN 16507-2 Schriften – Schriftgrößen – Teil 2: Textverarbeitung, Mediengestaltung und verwandte Techniken kann ab sofort über das Norm-Entwurfs-Portal kommentiert werden, die Einspruchsfrist endet am 23. Oktober 2019.
OpenMoji 12.0 – jetzt lückenlos

Open-source-Emoji für Designer, Entwickler und den Rest der Welt
Emoji sind für viele Menschen in der täglichen Kommunikation unverzichtbar. Sie beugen Missverständnissen vor 👍, können ziemlich lustig sein 😆 und manchmal ganz schön bizarr 💩🤪🙀🧟. Für über 50 Studierende an der HfG Schwäbisch Gmünd sind Emoji jedoch weit mehr als bunte Bildchen, die Kurznachrichten aufpeppen. Die Projektgruppe OpenMoji sieht sie als Teil einer wichtigen und spannenden Entwicklung, der »Rückkehr der Bildzeichen in die geschriebene Kommunikation«. Zum ersten Mal in der Geschichte der Menschheit sei es möglich, mit einer Kombination aus Laut- und Bildzeichen zu kommunizieren. So ließen sich Dinge sagen und Tonalitäten vermitteln, wie es bisher nicht möglich war.
Nach Auffassung der Leiter von OpenMoji, Daniel Utz undBenedikt Groß, sei die kreative Vielfalt der Emoji aktuell eher begrenzt, »vor allem im Vergleich mit der unglaublichen Anzahl an verfügbaren Schriftarten«. Im Moment gäbe es lediglich ein Dutzend Emoji-Sets, die meisten davon werkeln in den mobilen Betriebssystemen der großen Technologie-Unternehmen. Ihr Nachteil: gestalterisch orientieren sie sich an den grafischen Stil der jeweiligen Software-Umgebung und in Sachen Kompatibilität und Nutzungsrechte sind sie restriktiv ausgestattet.

»Deshalb haben wir OpenMoji als bisher einziges konzernunabhängiges Emoji-System entwickelt. Bei der Gestaltung des OpenMoji System haben wir visuelle Guidelines entwickeln, die nicht an ein bestimmtes Branding gekoppelt sind. Ausserdem war es unser Ziel, Emoji zu entwerfen, die sich visuell besser in Text integrieren.« betont Benedikt Groß, anlässlich eines Meilensteins seiner Initiative.
Denn eineinhalb Jahre nach dem Start des Projekts erfüllen die OpenMoji nun den vollständigen Unicode Emoji 12 Standard. Über 50 Studierende der HfG Schwäbisch Gmünd haben zusammen mit zwei Professoren das gemeinsame System mit insgesamt 3180 Emoji entwickelt, inklusive sämtlicher Flaggen 🇬🇭🏴🇪🇺, Skintones 👨🚀 > 👨🏻🚀👨🏼🚀👨🏽🚀👨🏾🚀👨🏿🚀 und Gendervarianten 👩🧑👨. Jenseits des Standard-Unicode-Spektrums enthält OpenMoji auch Spezial-Kategorien zu Themen wie Technologie und Design.
Und das OpenMoji Projekt geht weiter. Im nächsten Schritt wird sich das Team mit der Weiterentwicklung ihrer Plattform und der Zukunft der Emoji beschäftigen. Weltweit haben Menschen ein riesiges Interesse an den Zeichen, mit denen sie täglich kommunizieren. Mit OpenMoji soll ihnen eine gemeinsame, offene Plattform zur Verfügung stehen. Daniel Utz und seine Studierenden hoffen auf vielfältige Beiträge und Input aus unterschiedlichen Disziplinen.


»Kribbeln im Kopf« eBook, kostenlos für Fontblog-Leser

Vor 18 Jahren entwickelte der österreichische Berater Mario Pricken ein neues Kreativitätsmodell. Kurz zusammengefasst: Ideen sind kein Zufall, sie lassen sich systematisch herleiten, Kreativität trainieren auf Basis von rund vierzig Prinzipien. Sein Buch »Kribbeln im Kopf« verkaufte sich weltweit in sieben Sprachen, fast 140.000 mal. 2012 erschien die 11. erweiterte Auflage und dazu das spielerische Arbeitstool »Creative Sessions« (Fontblog berichtete: Pricken kribbelt wieder). Drei Jahre später folgte unter dem Titel »Trigger me« die iPad-App zum Buch, was uns zum Gespräch mit dem Design-Coach bewegte: »Kreativität lässt sich trainieren …«.
Letzte Woche schrieb mir Mario: »Ich möchte den Fontblog Lesern gerne mein ›Kribbeln im Kopf‹ gratis als eBook zur Verfügung stellen. Hier ist ein Link …«. Na wunderbar, warum länger warten: Kribbeln im Kopf für Fontblog-Leser (verknüpft mit der Anmeldung zu Marios Newsletter).
Pulpo – sympathische Clarendon für Lesetexte.

Design-Details von Pulpo: moderater Kontrast, vertikale Betonung, hohe, vertikale Abstriche
Neu aus dem Schriftlabor von Felix Braden (Floodfonts): Pulpo, eine gut lesbare Clarendon, mit dem Skelett von Century Schoolbook, in 5 Strichstärken plus echten Kursiven. Die Familie wurde von Felix auf Lesbarkeit getrimmt, was sich in vielen Designdetails niederschlägt. Längere Ober- und Unterlängen geben dem Text Luft zum Atmen und verbessern die Lesbarkeit von Fließtexten. Trotz typischer Slab-Serif-Stabilität im Design, wirken die Formen freundlich, wobei sich in vielen Details der handgemachte Charakter offenbart. Die Buchstaben wecken vertraute Erinnerungen und wirken ein wenig nostalgisch – wie aus der guten alten Zeit.
Die komplette Pulpo-Familie besteht aus 10 Schnitten, von Light bis Black (einschließlich Kursiven) und eignet sich vor allem für Editorial-Design, Werbung und Verpackung sowie für die Web- und App-Entwicklung. Ein massiver, stabiler Aufbau in Kombination mit einem geringen Strichstärkenkontrast, betont die horizontalen Elemente, und macht Pulpo zur perfekten Wahl für Lesetexte am Bildschirm und kleine Schriftgrößen auf Naturpapier.

Erstaunlich gut lesbar in Lesetexten, eine der Stärken der neuen Slab-Serif Pulpo
Jeder Schnitt enthält 489 Glyphen, Versal- und Mediävalziffern für Fließtext und Tabellensatz sowie mathematische Zeichen und gängige Währungszeichen. Um den Bedürfnissen der globalen Kommunikation gerecht zu werden bietet Pulpo eine umfangreiche Sprachunterstützung für alle west-, ost- und mitteleuropäischen Sprachen
Entstehungsprozess
Wie alles begann, beschreibt Felix Branden so: »2017 entschied ich mich, einen ganzen Satz Glyphen für einen manuellen Druckvorgang zu schneiden, der später als digitalisierte Schrift namens Kontiki auf Myfonts und als Pulpo Rust bei Adobe veröffentlicht wurde (vergl. Fontblog: Neue, lebendige Holzdruck-Schriftfamilie Kontiki). Als Basis suchte ich eine fette Schrift nach dem Clarendon-Muster, die ich schließlich selbst auf der Grundlage einer meiner Lieblingsschriftarten, Century Schoolbook, zeichnete. Die Skizzen dieser Clarendon gefielen mir dann so gut, dass ich mich dazu entschied, die Zahl der Schnitte auszubauen, um Kursiven zu erweitern und als eigenständige Familie mit dem Namen ›Pulpo‹ auf den Markt zu bringen.«

Das merkt man Pulpo an: erst in Holz geschnitten, dann Probedrucke angefertigt und danach digitalisiert
Die erste Clarendon übrigens wurde 1845 von der Fann Street Foundry veröffentlicht. Sie wurde von Robert Besley entworfen und von Benjamin Fox geschnitten. Als fette Erweiterung für die Textschriften dieser Zeit geplant (eine Alternative zu Kapitälchen oder Kursiven als Hervorhebung) gab es ursprünglich keine leichten bzw. Text-Schnitte der Clarendon, und natürlich auch keine Kursive. Im folgenden Jahrhundert wurde Clarendon zum Modell für eine Vielzahl von Schriften (z.B. der ›Clarendon‹ von Hermann Eidenbenz und Freeman Craws ›Craw Clarendon‹), die für den Bleisatz konzipiert, für den Fotosatz erweitert, und dann im beginnenden DTP-Zeitalter in den 90er Jahren digitalisiert wurden.
Century Schoolbook hat sich über Jahrzehnte von den Vorbildern der Scotch-Schriften über eine Zeitungsschrift (Century) zu einem Standard für schulische Texte in den Vereinigten Staaten entwickelt. Heute ist sie ein Synonym für gute Lesbarkeit geworden und für Felix Braden die Quintessenz der amerikanischen Schrift. Da die Proportionen der Zeichen perfekt ausbalanciert sind, und sie ein freundliches, angenehmes Gefühl auslösen, schien sie eine gute Inspirationsquelle für seine Clarendon zu sein.

Korrekturblatt von Pulpo: Nach dem Probedruck begann die Detailarbeit
»Um die aufrechten Schnitte von Pulpo zu erstellen, zeichnete ich über das Skelett der Century Schoolbook und entwarf eine Clarendon, indem ich den Kontrast reduzierte und typische Elemente wie lange Aufschwünge und waagerechte Abschlüsse hinzufügte. Einige Buchstaben, z.B. Das a oder das g mussten komplett überarbeitet werden, da sich die Buchstabenform von der Clarendon-Tradition unterscheidet.« erinnert sich Felix Braden an die Detailarbeit.
Für die Italics sei Jonathan Hoeflers ›Sentinel‹ eine gute Inspirationsquelle gewesen, wobei Felix den Weg ging, seine Italics eher statisch als geschrieben zu entwerfen. Seiner Meinung nach hätte es Aldo Novarese mit seiner ›Egizo Serie Corsiva‹ etwas »zu weit getrieben«, während die Kursiven von Matthew Carters ›New Century Schoolbook‹ genau seine Kragenweite seien. Wichtiges Konstruktionsmerkmal sei der obere linke Abschluss des n in Pulpo Italic, wie in den Aufrechten eine Serife und kein hakenförmiger Abstrich. Auf der anderen Seite wurden die waagerecht geschnittenen Aufschwünge abgemildert und an die vom Schreiben abgeleitete Form angepasst.

Die Pulpo-Familie im Überblick: 5 Strichstärken plus echte Kursive, inspiriert von Jonathan Hoeflers ›Sentinel‹
Da die Schrift auch in längeren Texten gut lesbar sein sollte, entschloss sich Felix dazu, einige dekorative Elemente zu entfernen, die bei kleinen Textgrößen nicht wirklich funktionieren. Insbesondere die nüchternen Ziffern unterscheiden sich von den historischen Clarendon-Beispielen.

Die neue, sympathische Pulpo: beste Lesbarkeit, zurückhaltende Kursive, raffinierte Details
Über Felix Braden
Felix lebt und arbeitet in Köln. Er hat an der Fachhochschule Trier Kommunikationsdesign bei Andreas Hogan studiert und mit Jens Gehlhaar bei Gaga Design gearbeitet. Er war eines der Gründungsmitglieder von Glashaus-Design, und arbeitet zur Zeit als Art Director bei MWK Cologne und als freischaffender Schriftgestalter. Im Jahr 2000 gründete er die Foundry Floodfonts und gestaltete viele kostenlose Schriften die über Adobe Typekit verfügbar sind (Moby, Bigfish, Hydrophilia, u.a.). Seine kommerziellen Schriften werden vertrieben vom Fontshop (FF Scuba), Floodfonts (Capri, Sadness, Grimoire), URW++ (Supernormale), Volcanotype (Bikini) und Ligature Inc (Tuna als Kooperation mit Alex Rütten). FF Scuba ist einer der Gewinner des Communication Arts Typography Annual 2013 und wurde in vielen Bestenlisten genannt darunter Typographica, Typefacts, Typecache und FontShop. Kontiki war für den German Design Award 2019 nominiert.