Warum eine eigene Coronavirus-Statistik?
Drei schnelle Antworten vorweg:
- Weil ich die Vergangenheit festhalten möchte
- Weil ich die Gegenwart verstehen möchte
- Weil ich in die Zukunft blicken möchte
Und dies alles zusammen liefern mir weder die Statistiken der Meldestellen, noch der Medien.
Wie so oft begann bei mir alles mit einer Unzufriedenheit über die Gestaltung der „amtlichen“ Charts: Schrift, Farbe, Übersichtlichkeit. Bald merkte ich, dass die von den Medien gelieferten Statistiken auch meine Fragen nicht beantworteten. Schließlich erwachte der Forschergeist in mir, weil ich mich an die tagelangen Messungen und Kurven während meines Physikstudium erinnerte, aus denen ich belastbare Ergebnisse herauszulesen versuchte.
Die erste Visualisierung der Covid19-Entwicklung, die Anfang März die große Runde im Netz machte, war die schwarze Landkarte mit den roten Luftballons, ins Netz gestellt von der Johns Hopkins University (Baltimore, Maryland, USA): COVID-19 tracking map. Diese und andere Statistiken (zum Beispiel des Robert Koch Instituts) nehmen drei Parameter unter die Lupe: (1) die Anzahl der registrierten Fälle, die (2) Summe der Verstorbenen und die (3) Zahl der Genesenen, wobei die beiden letzteren übrigens Untermengen von (1) sind, also darin enthalten. Was mir bei diesen Karten fehlte, war der zeitliche Verlauf.
Leider ist gerade die erste Variable (Fallzahl) die unsicherste. Sie basiert auf den Ergebnissen von Tests, die in den einzelnen Ländern sehr unterschiedlich gehandhabt werden. Weil es die Kapazität des Gesundheitswesens nicht leisten kann, alle Menschen (mit oder ohne Symptome) zu testen, muss eine Auswahl getroffen werden. Flussdiagramme helfen bei der Entscheidung, ob man überhaupt eine Chance auf einen Test hat (hier ein Beispiel auf Zeit Online: Habe ich mich mit dem Coronavirus angesteckt?).

Die Covid-19 Tracking-Karte der Johns-Hopkins-Universität dient vielen Experten als Datenquelle für die Beobachtung der Coronavirus-Pandemie-Entwicklung
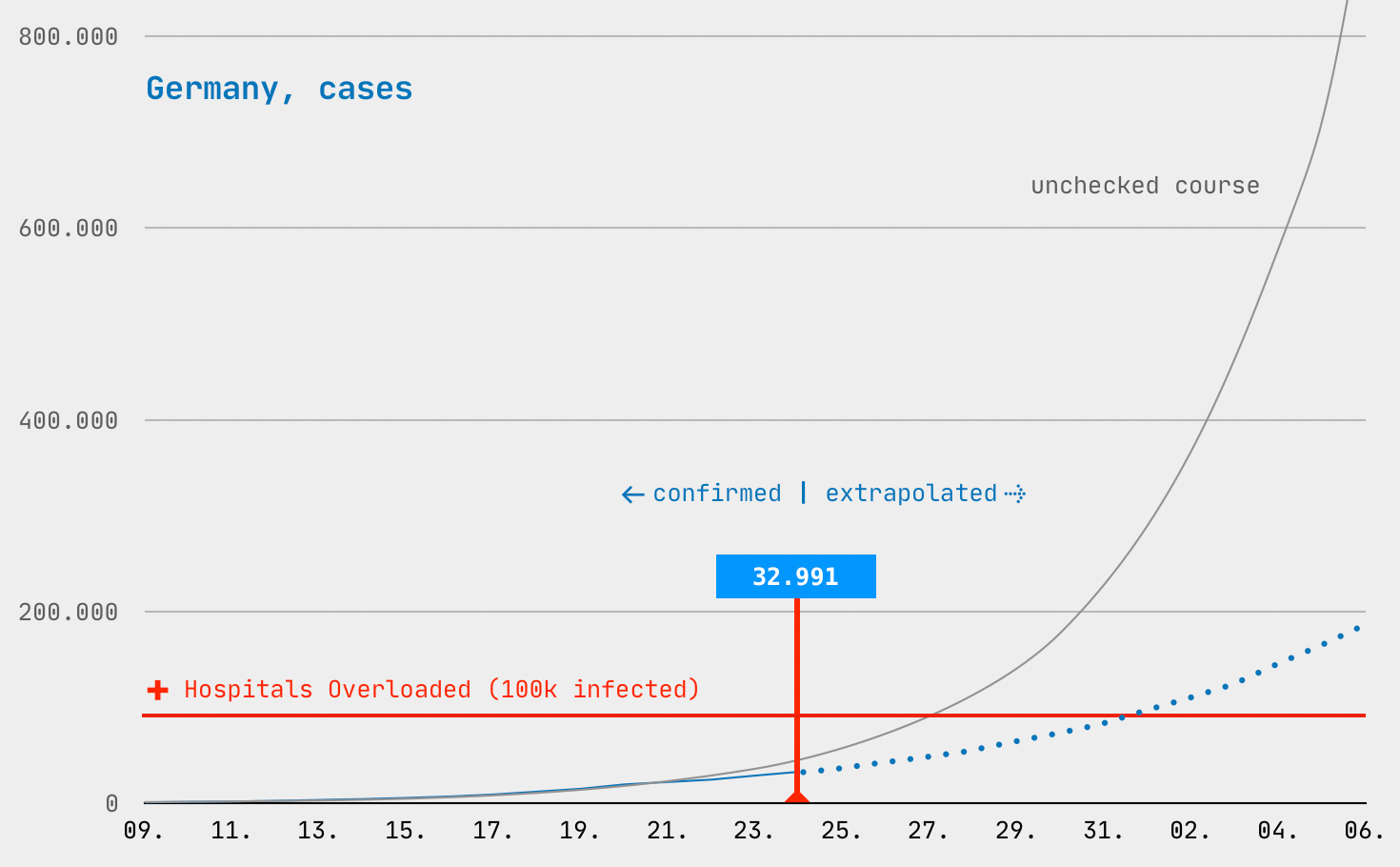
Es ist also davon auszugehen, dass weit mehr Menschen mit dem Coronavirus infiziert sind, als die statistische Zahl der registrierten Fälle wiedergibt. Wie hoch diese Dunkelziffer ist, weiß derzeit niemand. Was allerdings ziemlich zuverlässig gezählt wird, ist die Zahl der Verstorbenen. Die aktuell vergleichsweise geringe Zahl der Toten in Deutschland (heute 159, bei 33.000 registrierten Fällen) weist laut Experten darauf hin, dass in Deutschland mehr getestet wird als zum Beispiel in Spanien (2991 Tote, 42.000 Fälle) oder in den USA (801 Tote, 55.000 Fälle); so lässt sich erahnen, in welchen Dimensionen sich die registrierten Fälle dieser beiden Länder tatsächlich bewegen müssten … sie stehen noch vor großen Herausforderungen.
Wichtig ist auch zu erwähnen, dass die Zahl der registrierten Fälle bezüglich des Fortschritts der Pandemie immer ein Blick zurück ist. Das ergibt sich aus der Inkubationszeit des Virus (5 – 6 Tage), plus der Zeit für den Test, das Warten auf das Ergebnis, das Melden an die Gesundheitsämter und deren Veröffentlichung … alles in allem 10, wenn nicht gar 12 Tage.
Warum nehme ich die Daten von Johns Hopkins und nicht die vom Robert Koch-Institut?
Mir fiel von Anfang an auf, dass die Zahlen von Johns Hopkins nicht nur die höheren waren, sondern auch übers Wochenende konstant weiterliefen, wenn Gesundheitsämter nur spärlich besetzt sind. Der Grund: Johns-Hopkins-Mitarbeiter suchen und zapfen aktiv öffentlich zugängliche Quellen ab, zum Beispiel die Internetseiten von Gesundheitsbehörden, die Website der WHO, und laut welt.de „auch eine Community von Medizinern, die Medienberichte und Twitteraccounts von Behörden analysieren. Damit geben die Zahlen der Johns-Hopkins-Universität nahezu in Echtzeit das Lagebild wieder.“ So ähnlich würden das auch andere Datensammler machen, zum Beispiel Risklayer. Die WHO-Daten stammten von den nationalen Behörden und geben den Datenstand von 10 Uhr mitteleuropäischer Zeit wieder.
Um abschätzen zu können, welche Maßnahmen gegen die Corona-Pandemie sinnvoll sind, benötigen Politik und Wissenschaft verlässliche Daten. Doch wie auch der SPIEGEL gestern feststellte: Die Fallzahlen des Robert Koch-Instituts (RKI) hinken der Realität teils mehrere Tage hinterher (Die große Meldelücke). Unser föderales System bringt es mit sich, dass in den Bundesländern unterschiedliche Behörden die Daten erfassen, bündeln und zu verschiedenen Zeiten veröffentlichen. Generiert werden die Daten in Testlaboren, die Coronafälle innerhalb von 24 Stunden an die örtlichen Gesundheitsbehörden melden, also Stadt oder Landkreise. „Das geschehe in der Regel per Fax“ zitiert der SPIEGEL einen Behördenmitarbeiter. Daraufhin werden sie händisch in ein digitales Meldesystem eingegeben, das sie an die Landesbehörden übermittelt. Diese importieren die Fallzahlen in eine Datenbank und senden sie um 15 Uhr an das RKI.
Ich nutze die Zahlen von Johns Hopkins, die ich einer ziemlich gut gestalteten und gepflegten interaktiven Website der Berliner Morgenpost entnehme: Coronavirus Echtzeitkarte. Dort ist auch ein hilfreicher Rückwärts-Schieberegler integriert.
Die Spielregeln der Virus-Pandemie
Ich habe mit meiner Statistik vor rund drei Wochen begonnen, als die ersten Maßnahmen beschlossen wurden: ein Fußball-Bundesligaspiel ohne Zuschauer, die Eishockey-Liga brach gerade ihre Saison komplett ab, Berlin schloß alle Opern und Theater, Businesskonferenzen werden reihenweise abgesagt und am Abend gab James Blunt sein Konzert in Hamburg vor leeren Rängen. Alles begann mit einer simplen Tabelle, in der ich die aktuellen und zurückliegende Fallzahlen und Todesfälle eintrug, für Deutschland und Berlin. Dem hoch geschätzten Podcast von NDR Info Das Coronavirus-Update mit Christian Drosten habe ich an diesem Tag entnommen, dass sich die Epidemie – basierend aus den Erfahrungen in China und Italien – nach folgenden 3 Spielregeln ausbreitet:
- Die Zahl der gemeldete Fälle verdoppelt sich alle 3 Tage
- Die Zahl der gemeldeten Fälle ist in 3 Wochen die Zahl der Toten und/oder
- Die Zahl der Toten verdoppelt sich alle 2 Tage
Das ist die Ausbreitungsmathematik für eine ungebremste Entwicklung des Coronavirus. Und sie verläuft exponentiell, denn nichts anderes bedeutet multiple Verdopplung: 2 hoch n, oder auch 2ⁿ geschrieben. Es fällt uns Menschen schwer, die Dramatik eines exponentiellen Wachstums zu verstehen. Unser Gehirn kann nur linear. Mancher erinnert sich vielleicht an die Anekdote vom indischen Kaiser Sheram, der den Erfinder des Schachspieles belohnen wollte, weil er großen Gefallen an dem Spiel fand. Der Erfinder sollte einen Wunsch äußern, worauf dieser sagte: „Händige mir für das erste Feld des Schachbrettes 1 Reiskorn aus, 2 Körner für das zweite Feld, 4 für das dritte und für jedes weitere Feld doppelt so viele Körner wie für das vorhergehende“. Der Kaiser fühlte sich gekränkt, da ihm das Ausmaß des Wunsches noch nicht bewusst war. Als digitalisierte Menschen, Freunde des Dualsystems und Käufern von Computern ist uns die Zahlenreihe 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 und 1024 durchaus bekannt und wir wissen daher, dass auf dem 10. Feld des Schachbretts bereits 512 Reiskörner liegen, summiert mit den Feldern davor sind das 1023 Reiskörner. Kurz und gut: die Reiskornzahl des 64. Feldes liegt über 9 Trillionen (eine 19-stellige Zahl), die Anzahl der Reiskörner auf allen Feldern ist 20-stellig. Bei 3 g Gewicht pro Reiskorn ergeben sich 540 Milliarden Tonnen Reis, was 873 Jahresernten Reis entspricht. Danke an Jennifer, Theresa, Sabrina, Charlina & Birte von der TU München fürs Ausrechnen (PDF).
Zurück zur Entwicklung der Coronavirus-Fallzahlen in Deutschland. An dem Tag, als ich meine Tabelle begonnen habe (12. März), lag die Zahl der gemeldeten Fälle bei 2.745, drei Tage später bei 5.813, wieder drei Tage später bei 12.327 … ich habe später noch die Woche zuvor erfasst und festgestellt, dass sich die Zahl der Fälle über zwei bis drei Wochen wie ein Uhrwerk gemäß den Vorhersagen entwickelt hatte.
Das war die Zeit, als Bundesgesundheitsminister Jens Spahn täglich vors Mikrofon trat und sofortige Maßnahmen forderte. Was er nicht sagte, aber wusste: Entwickeln sich die Fälle und die Todeszahlen ungebremst weiter wie bisher, hätten wir in Deutschland am Ende der ersten April-Woche bereits 1 Million gemeldeter Fälle und rund 20.000 Tote. Das sagte mir jedenfalls meine Tabelle, die ich zu dieser Zeit noch nicht mit den April-Zahlen auf Twitter veröffentlichte, sondern nur bis zum 31. März.
Was ich aber tatsächlich mit meiner eigenen Tabelle herausfinden wollte, und das ist keiner mir bekannten Statistik zu entnehmen: Wann und wie stark greifen die Maßnahmen, die zunehmend schärfer wurden, bis zur Kontaktsperre vor 3 Tagen? Dazu braucht es nur zwei Kurven (siehe oben), nämlich die ungebremste und die gemeldete Entwicklung (vom Fällen und Toden), wobei ich die gemeldeten Zahlen ab jedem Stichtag hochrechnete, mit der gerade geltenden Wachstumsrate. Seit Sonntag liegt die Wachstumsrate unter 2.0 (also keine Verdopplung mehr), aktuell liegt sie bei den Fällen bei 1.5 und bei den Toden bei 1.4.
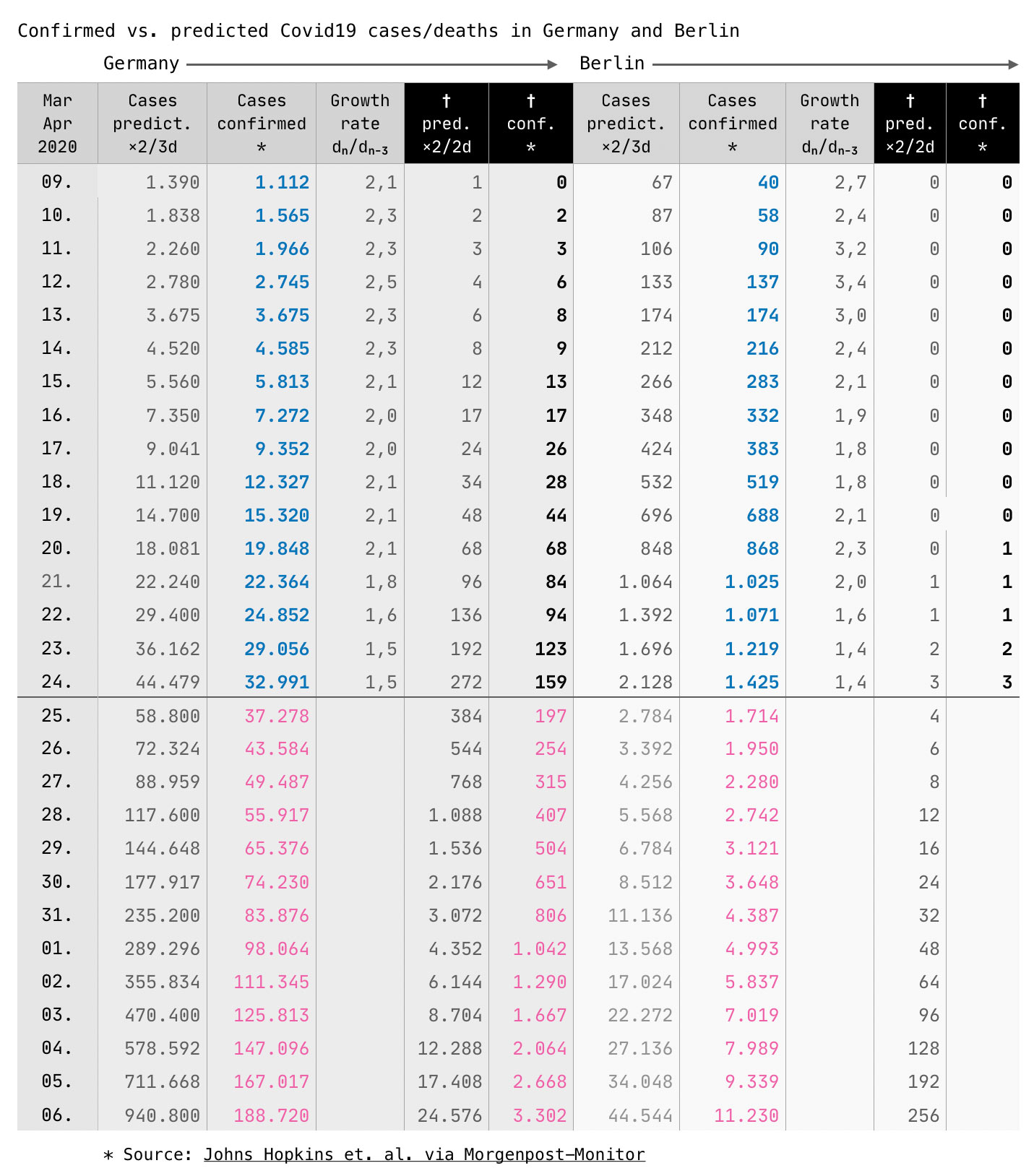
Meine tägliche Coronavirus-Tabelle für Deutschland und Berlin stellt die bestätigten Fälle (blau) und Tode (schwarz) den internationalen Erfahrungswerten für ungebremste Ausbreitung gegenüber (grau); in magenta die Hochrechnungen, basierend auf den am Stichtag geltenden (gebremsten) Wachstumsraten.
[wird fortgesetzt]
Deep Speed Typography

Drei Semester Zeit für ein eigenes Typografie-Projekt. Workshops, Exkursionen, Teamarbeit: Der neue Master der Hochschule Mainz startet im Oktober 2020. Virtueller Info-Termin am 1. April 2020.
Es gibt typografische Gestaltung für das tiefe Verständnis (Deep Reading) und Typografie für den schnellen Überblick (Speed Reading). Beide Lesearten und ihre visuelle Aufbereitung sollen in einem neuen Masterstudiengang der Hochschule Mainz intensiv beleuchtet werden. Dabei wird mittels gestalterischer Experimente zunächst ermittelt, worauf sich ein eigenes Master-Projekt fokussieren könnte: Ein besseres Instagram, eine eigene Schrift, die Lese-App der Zukunft, ein generatives Buch, Typografie für Augmented Reality, Moving-Posters, das Editorial Design von morgen oder das, woran noch niemand gedacht hat.
Der Master richtet sich sowohl an Typografie-/Editorial Design-Nerds als auch an diejenigen, die noch etwas nachholen wollen: typografische Expertise, technische Hintergründe, Nachdenken über Gestaltung — oder einfach mehr Projekterfahrung. Solche Studiengänge dienen darüber hinaus als solide Kontaktbörse für den Einstieg ins Berufsleben.
Mit Workshops von Jakob Runge (Schriftentwerfer), Frank Rausch (Interface-Typograf) und Underware (Foundry).